Production ML workloads often require very large compute and system resources, which leads to the application of distributed processing on clusters. On premises or cloud-based infrastructure cost requires maximum efficient use of resources. This makes distributed processing pipeline frameworks such as Apache Flink ideal for ML workloads.
In addition, production ML must address issues of modern software methodology, as well as issues unique to ML. Different types of ML have different requirements, often driven by the different data lifecycles and sources of ground truth. Implementations often suffer from limitations in modularity, scalability, and extensibility.
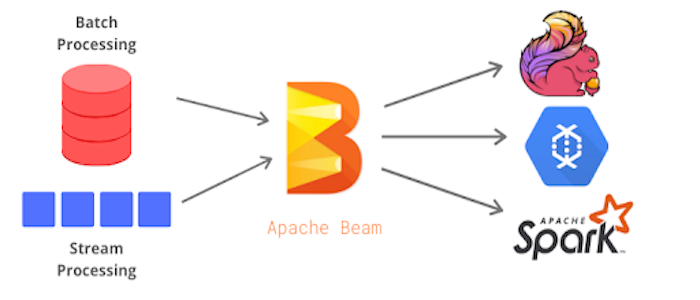
In this talk, we discuss production ML applications and review TensorFlow Extended (TFX), Flink, Apache Beam, and Google experience with ML in production.
This is the 6th talk in the series. Do not forget to sign up to the other sessions on Beam learning month:
May 6 - Interactive Introduction to Apache Beam. Session 1
May 13 - Best practices towards a production-ready pipeline. Session 2
May 20 - Introduction to the Spark Runner. Session 3
May 27 - The Best of Both Worlds: Unlocking the Power of Apache Beam with Apache Flink. Session 3
Jun 3 - Feature Powered by Apache Beam – Beyond Lambda. Session 5
All the resources used during the presentation and links to the recording will be posted here:
https://github.com/aijamalnk/beam-learning-month