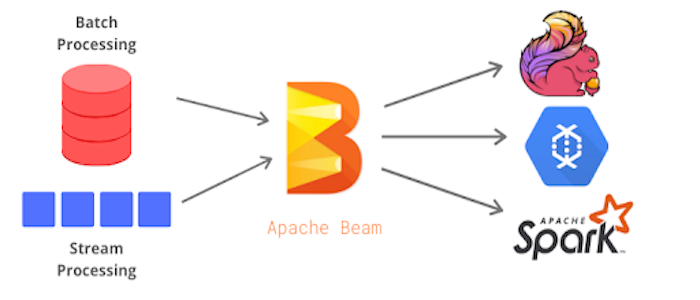

In this talk we introduce Apache Beam users to the Spark runner and discuss why it is a perfect match for users who care about running their data jobs in an open source system that allows jobs to be run in different clusters and clouds.
This is our 3rd talk in the series, donot forget to check out Webinar 1 on May 6 on Interactive Introduction to Apache Beam Session 1 and Webinar 2 on May 13 on Best Practices Towards a Production-ready Beam Pipeline Session 2.