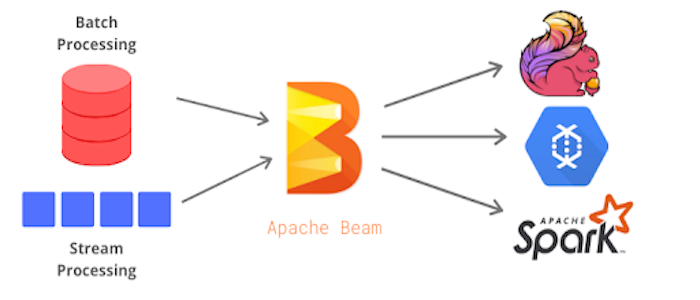

Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Apex, Apache Flink, Apache Spark, and Google Cloud Dataflow.
This is session 1 of the series:
In this talk, we will be introducing Apache Beam using Jupyter Notebooks by live coding both a batch and streaming pipeline using publicly available COVID-19 data.
For more talks on Apache Beam, join the Session 2 on May 13th, 10am PST. Link